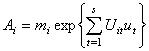Exemple de fichier d'entrée :
5.d0 Beta .9 Remplissage .2 Mu sans U/2 100 Nb points entree (TRAN) 4.d0 U 10 N dimmension X 10 M dimmension Y 501 Nb points sortie (nw) -10 wmin (0. pour les bosons) 10 wmax 20 Nb de valeurs de alpha (nalpha) 0.01 Alpha1 8 Alpha2 900 Nb d'iterations (niter) 4 Nb de vecteurs d'onde 6 Nb options (nopt) y Matrice de covariance n Imposer la symetrie de G y Moments du modele par defaut n Doubler le nobmbre de mesures n Calculer le facteur de Scaling y Calculer l'incertitude --------------------------------------- Vecteurs d'onde et scaling KX KY Scaling Alpha 1 1 1 5 2 9 1.5 7.6 2 7 13.4 4 3 5 2 22 4 3 1 .01 5 1 10 0 ---------------------------------------- |
Critères de validation: